0. 들어가며
종목별 과거 주가 조회 API의 응답 지연 문제가 있었고 변동성이 낮은 데이터라는 특성을 고려해 Redis 캐싱을 적용해 응답 속도를 약 30% 개선했었습니다.
하지만, 외부 인프라에 의존하기에 앞서 데이터베이스(RDBMS) 자체의 성능을 어느 수준까지 끌어올릴 수 있을지를 확인해보고 싶었습니다. 단순히 데이터를 메모리에 올려 반환하는 방식보다 병목의 원인이 되는 쿼리 실행 계획을 분석하고 개선하는 것이 보다 기본적인 접근이라고 생각했습니다.
도메인별로 서버가 분리된 MSA 환경에서 주식 서비스를 독립된 환경으로 격리하여 테스트를 진행한 기록입니다. 병목을 재현한 뒤 추가적인 인프라 도입 없이 인덱스 설계 변경만으로 조회 성능을 31초에서 0.009초까지 개선한 과정입니다.
1. 문제 상황: 500만 건 데이터의 정렬 지연
사용자가 가장 빈번하게 조회하는 '종목별 과거 시세 조회' 기능에서 병목이 발견되었습니다.
1-1. 대상 데이터
문제가 발생한 곳은 일별 주가 정보를 저장하는 테이블이었습니다.
프로젝트 초기의 누적 데이터는 50만 건 수준이었으나, 매일 전 종목의 시세가 쌓이는 구조입니다. 이에 현재 데이터 양에 안주하지 않고, 향후 데이터가 수백만 건 이상으로 폭증했을 때도 서비스가 안정적일지 검증하고 싶었습니다.
따라서 테스트 환경에 데이터를 약 10배 증폭시켜 부하 상황을 시뮬레이션했습니다. 특히 병목이 예상되는 특정 종목(삼성전자)에는 약 100만 건의 데이터를 적재하여 추후 분봉/틱 단위 차트로 고도화될 경우까지 대비한 선제적인 스트레스 테스트를 수행했습니다.
1-2. 병목 쿼리
SELECT * FROM daily_stock_history
WHERE stock_code = '005930' -- 삼성전자 (종목코드)
ORDER BY daily_stock_history_date DESC
LIMIT 90;
1-3. 장애 현상
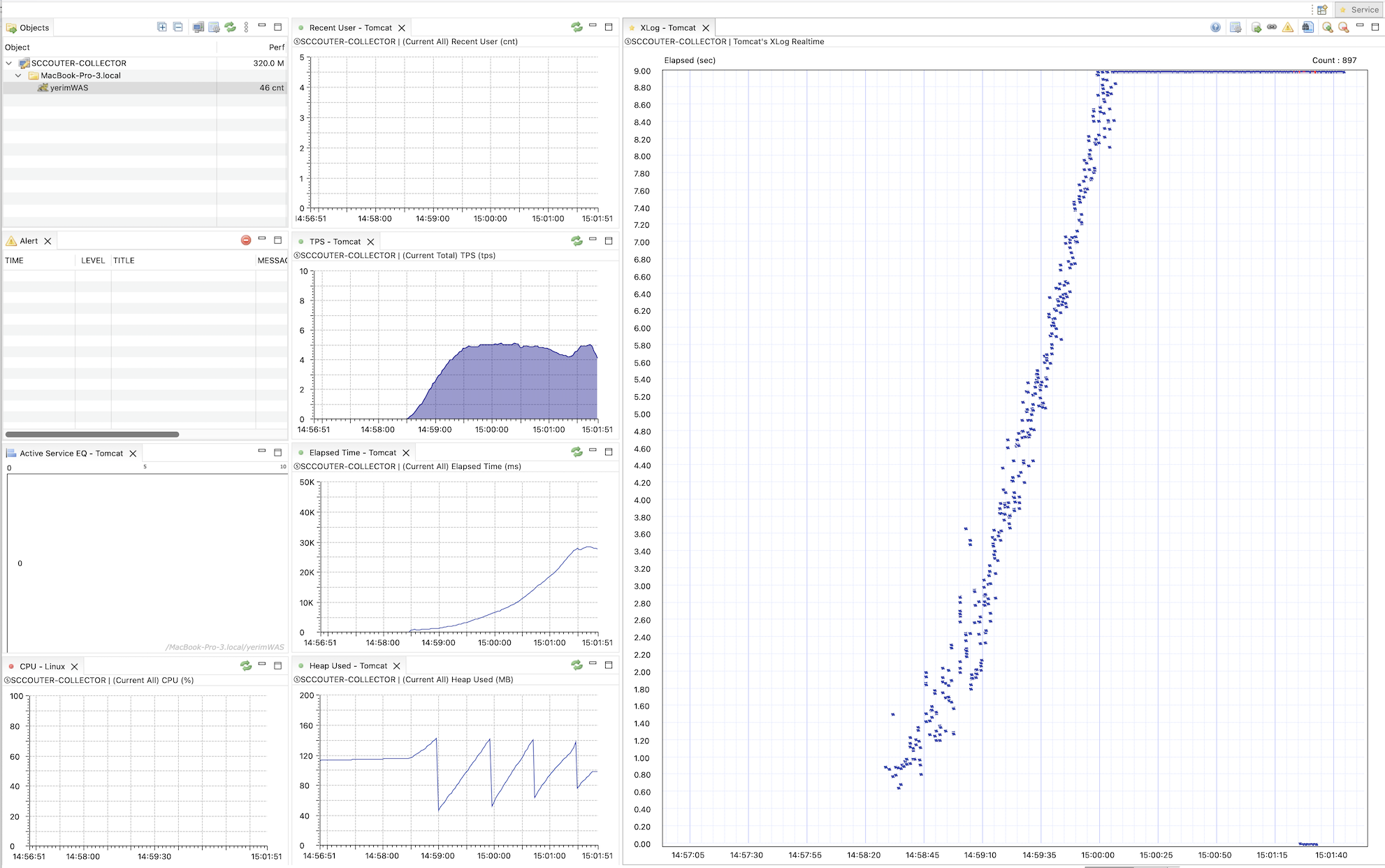
부하 테스트(k6) 결과, 동시 접속자가 50명을 넘어서자 응답 속도가 기하급수적으로 느려지며 시스템 장애로 이어졌습니다.
- p95 기준 응답 속도: 31.75s
- 처리량(TPS) : 약 4.5 TPS
- 150명의 가상 유저(VUser)가 요청을 보내고 있음에도 서버는 초당 4건 정도밖에 처리하지 못했습니다. Filesort 작업이 DB 자원을 독점하면서 병목이 발생했기 때문입니다.
- 에러율: 1.13% (타임아웃 발생)
- 로그: 쿼리 처리가 지연되면서 DB 커넥션 풀(HikariCP)이 고갈되어 SQLTransientConnectionException 발생

2. 테스트 환경
정확한 원인 분석을 위해 MacBook Pro와 Mac Mini를 1:1로 직접 연결하여 하드웨어 자원을 완벽히 격리한 로컬 테스트 환경을 구축했습니다.
2-1. 물리적 구성
- Target Server: MacBook Pro (M2 Chip)
- 역할: 실제 서비스 트래픽 처리
- 실행 프로세스: WAS, MySQL, Scouter Host / Java Agent
- 요청 처리에만 자원을 집중하도록 구성
- Load Generator & Monitor: Mac Mini
- 역할: 부하 생성 및 데이터 수집 / 관제
- 실행 프로세스: k6 (부하 테스트 스크립트), Scouter Server(Collector), Scouter Client
- 부하 발생과 로그 수집에 필요한 리소스가 Target Server의 CPU를 점유하지 않도록 분리
2-2. 네트워크 구성
- 순수한 DB 쿼리 성능과 네트워크 I/O만을 측정하기 위하여 L2 스위치로 LAN을 구성했습니다.
2-3. 테스트 시나리오
실제 사용자 유입 패턴을 고려하여 k6로 계단식 부하 시나리오를 설계했습니다.
- 목표: 시스템이 버틸 수 있는 최대 처리량과 임계점 확인
- 성능 기준: p95 응답 속도 500ms 이하, 에러율 1% 미만
[테스트 단계 구성]
- Warm-up (10명)
- Load (50명): 평시 트래픽 상황 가정
- Stress (150명): 트래픽 폭증 상황 가정 → 이 구간에서 DB CPU가 포화되고 병목이 발생하는지 관측
export const options = {
// [Step Load 패턴 적용]
stages: [
{ duration: '30s', target: 10 }, // 1. Warm-up: 10명으로 가볍게 시작
{ duration: '1m', target: 50 }, // 2. Load: 50명까지 증가 (평시 트래픽)
{ duration: '1m', target: 150 }, // 3. Stress: 150명으로 폭증 (병목 재현 구간)
{ duration: '30s', target: 0 }, // 4. Cool-down: 종료
],
// [성능 목표 설정: SLA]
thresholds: {
// "95%의 요청이 500ms 안에 들어와야 성공" -> 인덱스 미적용 시 이 기준을 초과하여 Fail 발생
http_req_duration: ['p(95)<500'],
// "에러율은 1% 미만이어야 함"
http_req_failed: ['rate<0.01'],
},
};
3. 원인 분석: 실행 계획 점검
장애 재현 직후, 쿼리의 실행 계획을 확인해보았습니다.

3-1. 대용량 데이터의 정렬 부하
실행 계획의 Sort 단계에서 약 100만건의 데이터가 처리되고 있음이 확인되었습니다.
- 상황: stock_code 인덱스를 통해 '삼성전자' 데이터를 찾았지만, 정렬 기준인 날짜(date)에 대한 인덱스는 없었습니다.
- 동작: DB는 추출된 100만 건을 정렬하기 위해 메모리(Sort Buffer)를 할당했으나 용량을 초과하여 디스크에 임시 파일을 생성해 정렬하는 Filesort 작업을 수행했습니다.
- 문제: 메모리 처리보다 느린 디스크 I/O가 발생하면서 쿼리 응답 시간이 30초 이상으로 치솟았고 과도한 CPU 자원을 소모했습니다.
3-2. 비효율적인 데이터 스캔
이 쿼리의 목적은 최신 데이터 90건을 조회하는 것입니다. 하지만 실행 계획을 보면 1,010,000건(Rows)을 읽고 있습니다.
- Read Rows: 약 1,010,000건 (대상 종목 전체 스캔)
- Result Rows: 90건 (상위 90개 추출)
단 90개의 결과를 얻기 위해 100만 개를 읽고 정렬한 뒤, 나머지 99.9%는 버려버리는 비효율적인 방식으로 동작하고 있었습니다. 이것이 CPU를 점유하고 DB 커넥션을 고갈시킨 원인이었습니다.
4. 해결 방법: 복합 인덱스
- WHERE 절의 조회 조건(stock_code)과 ORDER BY 절의 정렬 조건(daily_stock_history_date)을 결합한 복합 인덱스를 생성했습니다.
- 원리: 인덱스는 데이터가 정렬된 상태로 저장됩니다. 따라서 복합 인덱스를 활용하면 DB가 런타임에 별도의 정렬을 수행할 필요 없이, 이미 정렬된 데이터를 뒤에서부터 순서대로 읽기만 하면(Backward Index Scan) 됩니다.
CREATE INDEX idx_stock_history_code_date
ON daily_stock_history (stock_code, daily_stock_history_date);
4-1. 적용 시 고려사항 (Trade-off)
물론 인덱스 추가가 무조건적인 정답은 아닙니다. 인덱스를 적용할 때 두 가지 단점을 고려해야 했습니다.
- 쓰기 성능 저하: 데이터가 INSERT, UPDATE, DELETE 될 때마다 인덱스도 재정렬해야 하므로 쓰기 작업 부하가 증가.
- 저장 공간 증가: 인덱스 저장을 위한 별도의 디스크 공간을 차지.

전체 용량 대비 인덱스가 차지하는 비중은 약 12% 수준이었습니다. 주가 데이터는 장 마감 후 한 번 적재되면 수정이 거의 발생하지 않고 조회 트래픽이 압도적으로 높습니다. 따라서 12%의 저장 공간을 투자하여 조회 속도를 3,500배 개선하는 것이 비용 대비 효과 측면에서 합리적이라고 생각했습니다.
5. 결과
인덱스 적용 후, 동일한 격리 환경에서 성능을 측정한 결과입니다.
5-1. 정량적 결과
기존 단일 인덱스 환경과 복합 인덱스 적용 후의 성능을 비교했을 때, 약 3,500배의 성능 향상을 확인했습니다.
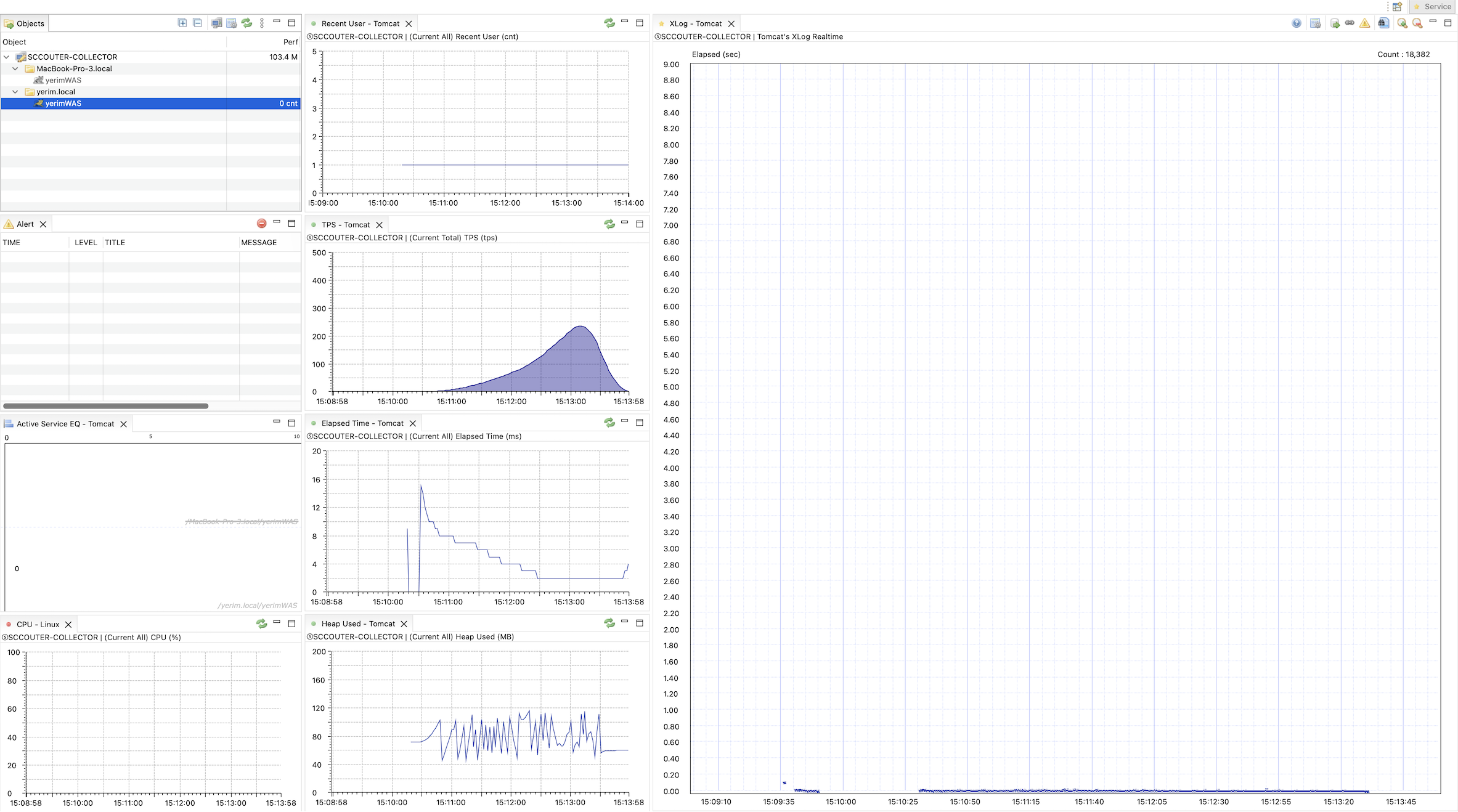
- 응답 속도: 31.75s -> 0.009s (p95 기준)
- 처리량(TPS): 4.5TPS -> 약 100TPS (20배 이상 증가)
- 기존에는 DB 병목으로 인해 요청을 처리하지 못하고 타임아웃이 발생했으나 개선 후에는 유입되는 트래픽을 지연 없이 안정적으로 처리
5-2. 실행 계획의 변화


- 개선 전: 인덱스에 정렬 정보가 없어 DB가 별도로 정렬을 수행하며 부하 발생.
- 개선 후: 인덱스가 이미 정렬되어 있어별도 정렬 없이 순서대로 읽기만 하여 부하 해소.
6. 마치며
이번에 성능 테스트를 하면서 단순히 기능만 구현하는 게 다가 아니라는 걸 느꼈습니다. 특히 옵티마이저(Optimizer)의 동작 원리나 Statement, PreparedStatement, CallableStatement 같은 기본 개념들도 다시 확실하게 정리해봐야겠다는 생각이 들었습니다.
'개발관련' 카테고리의 다른 글
| [Java] JDBC 인터페이스 분석: Statement vs PreparedStatement vs CallableStatement (0) | 2026.01.05 |
|---|---|
| WebSocket (2) | 2025.11.10 |
| [Spring Boot] Authentication & Authorization (2) | 2025.09.08 |
| Session, JWT, OAuth (0) | 2025.08.12 |
| static, Thread-safe (4) | 2025.08.04 |